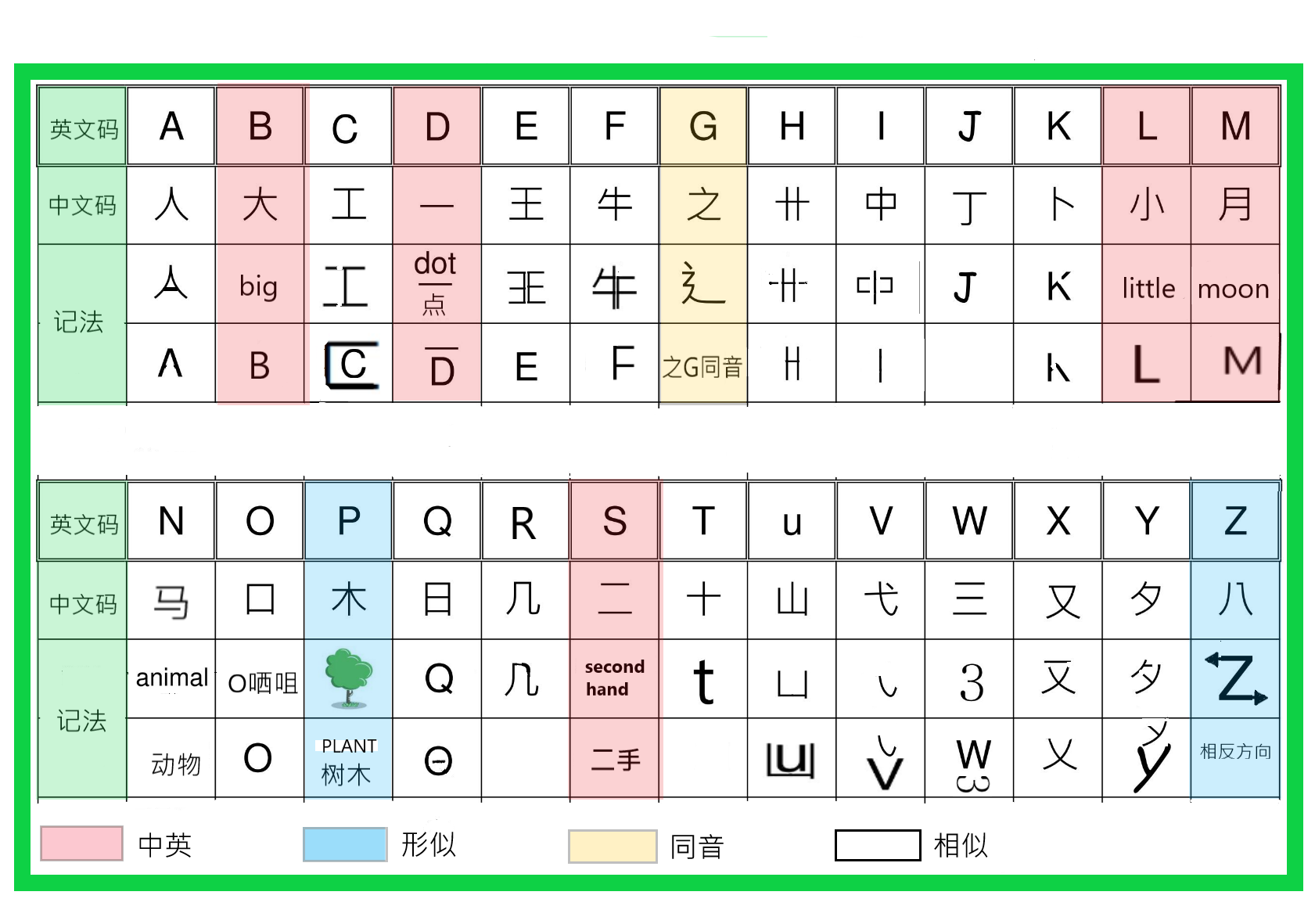
《字根码》以《字块底部》型态编码
《建成中文输入法》是以象形为主,总体是凭着感觉,无需强记,输入多了自然学会,绝不会再忘记。
《建成中文输入法》是以中文字的《字块》最底部笔划,或《最底部笔划》由下而上,最先接触相连的笔划之型态编码。
《字块》注解:《字块》是由整个中文字中,区分出来的一个或多个部份,即为《字的区块》。《建成中文输入法》是以《字块底部》型态编辑成26个字根码。
一个《字块》是笔划互相连结并合而成,在「整个字」中如有另外的其它《字块》,它们是互不接触的。
举例:<回>《字块》数目【2】、<冒>《字块》数目【2】、<贵>《字块》数目【2】、<宜>《字块》数目【2】、<层>《字块》数目【3】等。
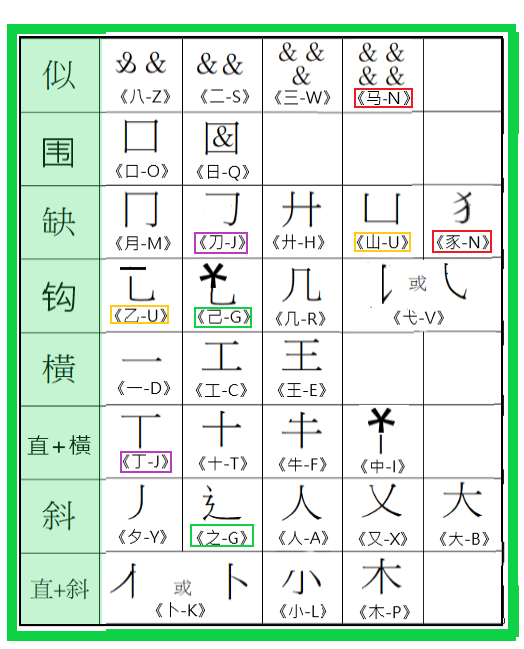
&表示:可以是任何笔划。
*表示:可以是任何笔划(但不包括横划或斜笔),通常是围型笔划。
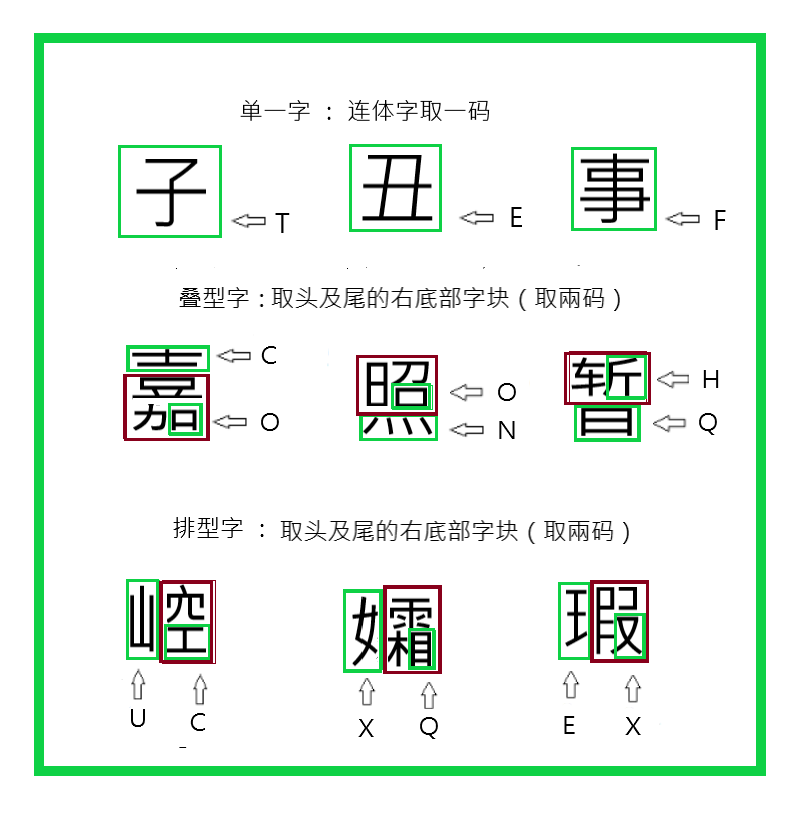
《排型字》和《叠型字》的区分:
《排型字》注解:《排型字》的《字块》就像多幢的楼房,一幢幢的由左至右一直排列开来。
举例:【排】、【倒】、【撇】等字。
《叠型字》注解:《叠型字》的《字块》就像单一幢的楼房,从顶层由上而下一层一层的走下来。
举例:【晕】、【辜】、【叠】等字。
《排型字》与《叠型字》的取码规定
《建成中文输入法》是以象形为主,总体是凭着感觉,无需强记,输入多了自然学会,绝不会再忘记。
**《建成中文输入法》是以中文字的《字块底部》型态编码。
由于中文字绝大部分为《排型字》,而《建成中文输入法》在《排型字》上取码是十分简单明确,不会含糊不清,故此取码判断很容易。
**建议起初学习时,先以《排型字》输入练习,从而熟记所有字根及字母,领略《建成中文输入法》的轻松简易使用,实在是最好的方法。
《排型字》取码规定:
由左至右分列取码,是以《字块底部》型态取码。
如果只有一列《字块》取一码,两列《字块》时则取两码。三个排列以上《字块》时,则取首列《字块》和尾列《字块》共两码。
《叠型字》取码规定:
由上而下分层取码,是以《字块底部》型态取码。
如果只有一层《字块》取一码,两层《字块》时则取两码。三个层次以上《字块》时,则取首层《字块》和尾层《字块》共两码。
#《叠型字块》的计算:
是以《明显分离的字块》合共有多少来决定。
原则上是如果没有《明显分离的字块》,就都只取单一码。
#《明显分离的字块》注解:
是两个绝对不会接触的《字块》,通常是一些具有横线的《字块》,由此构成两条平行线互不接触。
举例:
**两个《围型字块》、两个《横型字块》、《围型字块》+《横型字块》等,它们绝对不会接触。
《明显分离的字块》举例:
举例:<回>取【QO】、<冒>取【QQ】、<贵>取【DA】、<宜>取【MD】、<黄>取【CZ】等。
回《顶部》
《叠型字》的分层规定
《叠型字》虽然占比较少,但因《中文字体》设计上的问题,有时会有点上下《字块》混乱不清,要区分上下两部分的《字块》,必须有明确的规定,习惯取码的统一性,以免产生不明确的取码。
其中有三四个《字块》是有点跨越界限,就是《夕:Y》、《弋:V》和《之:G》、《又:X》等字根。
#《夕:Y》、《弋:V》等字根:
通常都位于字的顶部,因此有此《字块》在顶部都规定为《叠型字》,为《必取首码》。
**《夕:Y》举例:<房>取【YJ】、<层>取【YD】、<屋>取【YC】等字。
**《弋:V》举例:<感>取【VU】、<载>取【VF】等字。
#《之:G》、《又:X》等字根:
通常都位于字的底部,因此有此《字块》在底部都规定为
《排型字》,为最优先《必取首码》,比任何《字块》更优先取码。
**《之:G》举例:<莲>取【GF】、<逢>取【GF】、<避>取【GT】等字。
**《又:X》举例:<建>取【XF】、<翅>取【XS】等字。
回《顶部》
《叠型字》的《必取首码》
《必取首码》分类:
《必取首码》(第一层):共有五种类型
《叠型字》的《必取首码》的作用是减少重码字,相等于《明显分离的字块》。
- 《叠型字》同一层内有两个以上的《字块》,则称为《间隔分离层》,为《必取首码》。
#第一层为《间隔分离层》:
**有两个以上《相似的字块》:取本身《字块》
【S:二】竹花头:
举例:<等>取【ST】、<辔>取【SO】、<楚>取【SA】等字。
【H:廾】草花头:
举例:<艺>取【HU】、<花>取【HU】等字。
**有两个以上《不同的字块》:取右边《字块》
举例:<呆>取【P】__<架>取【OP】、<负>取【A】__<贸>取【JA】、<想>取【QU】、<帮>取【II】、等字。
#以上情况同样适用于第二层:
**如下层为《间隔分离层》,或有《明显分离的字块》,则会先取上层本身码。
举例:<雍>取【DE】、<齐>取【XS】、<率>取【DT】、<昂>取【QI】、<晷>取【QO】、<罚>取【QS】、<昆>取【QS】等字。
**或其它《明显分离的字块》,则会先取本身首码。
举例:<哀><衰>取【DV】、<昙>取【QD】、<冒>取【QQ】等字。
- 《围型首码字块》是《必取首码》,除非另有一下层为《联接字根》。
#《联接字根》注解:
即由「顶上部」以单一笔划逹至「底下部」的一个字根,如有则不会取《围型首码字块》,而联接成另外的一个字。
**《联接字根》举例:
例如:【木】、【生】、【儿】、【八】、【人】、【灬】、【女】、【大】、【七】、【寸】等。
#不取《围型首码字块》举例:
例如:<见>取【R】、<晁>取【R】、<早>取【T】、<星>取【E】、<要>取【X】、<呆>取【木】、<兄>取【R】、<只>取【Z】、<皂>取【U】、<贝>取【A】、<尊>取【T】、<煮>取【N】。
理由:下层为《联接字根》,合并成一个字,只有单一码。
#必取《围型首码字块》举例:
例如:<夏>取【QX】、<罩>取【QT】、<晃>取【QR】、<睾>取【QT】、<冕>取【QR】、<曷>取【QQ】、<暴>取【QL】、<皋>取【QT】、<辜>取【OT】、<界>取【QS】。
**理由:下层《非联接字根》,而《围型首码字块》是《必取首码》,如取多于两码时,首码必须是《围型首码字块》。
**留意:【戈】《非联接字根》,因其右边一定附带有一逗点在上,故被定义为《间隔分离层》,会先取上层本身码。
举例:<戛>取【QV】。
参考:以上《间隔分离层》。
**【大】虽偶然也会附带逗点在上,但因为不常有,不想取码时太费神分辨,应留待打完字才去拣选出来更好,故会将【大】定义为《联接字根》。
举例:<臭>取【B】、<类>取【B】。
参考:以上《联接字根》
#《相连笔划》和《联接字根》略有不同:
**《相连笔划》是不同层次《字块》组成,只令各《字块》合并为单一个字取码,但不可以令《围型首码字块》联接成为单一字取码。
举例:<幸>取【T】、<素>取【L】、<睾>则取【QT】、<冕>则取【QR】等字。
**《联接字根》则会令《围型首码字块》联接成为单一字取码。
举例:<尊>取【T】、<晁>取【R】等字。
#《字块底部》是《围形字块》呈现向上与下面分开的形状,亦为《必取首码》。
**例如:〈臼〉、〈山〉、〈凵〉等字。
**另外,〈凵〉与〈厶〉相似,虽然〈山〉取【U】,而〈厶〉取【D】,除了形态有点近似之外,逗点还有段落完结的意思,故此亦为《必取首码》,与《围型首码字块》运作条件一样相同。
---《不取首码》举例:<允>取【R】、<至>取【C】、<牟>取【F】。
---《必取首码》举例:<矣>取【DB】<台>取【DO】。
参考:以上《围型首码字块》
回:《顶部》
- 左和右两边具为斜笔,有撑开下层《字块》,呈分开形象:
**通常多是一些中心空下来的《字块》,使形成分离的形态。
【Z:八】八字头:
举例:<父>取【ZX】、<分>取【ZJ】等字。
【A:人】人字头:
举例:<令>取【AD】、<合>取【AO】等字。
【B:大】大字头:
举例:<奈>取【BL】、<春>取【BQ】等字。
【X:又】又字头:
举例:<务>取【XJ】、<蚤>取【XD】等字。
- 有包围起来的形象:
【M:月】帽子头:
举例:<字>取【MT】、「堂」取【MC】、「南」取【MT】、「突」取【MB】、<雪>取【ME】等字。
#还有些与帽子头【M:月】相对近似的字
例如:<欠>字的顶部,但只有〈右外邊〉呈《角狀》,〈左外邊〉是不呈《角狀》的,故取「刀:J」碼。
举例:<欠>取【JA】、<尔>取【JL】、<玺>取【JE】等字。
**留意:<今>不取【人刀:AJ】应取【人夕:AY】因斜笔有足够长度,明显呈撇型。
**特别留意:统一性取码,以上情况同样适用于简体字<买>取【JB】、<卖>取【JB】,唯<疋>取【A】。
理由:<买>取【JB】、<卖>取【JB】,是由于第二层亦为《间隔分离层》,故首码应定为《必取首码》。
**<疋>仍然只取【A】,是因为《乛》虽然为《必取首码》,但在中文字里作为首码是唯一的,就只独有这一个字,为免错判为《一》,方便简单取【A】码好了。
参考:以上《间隔分离层》。
【弋:V】弋字头:
举例:<感>取【VU】、<载>取【VF】等字。
【Y:夕】厂字头::
举例:<历>取【YJ】、<居>取【YO】、<启>取【YO】等字。
**留意:《撇型字块》位于顶部的最左边,其右边《横划字块》或其它《字块》,必须「占据整个顶部」。
#《撇型字块》必须位于顶部的最左边,假如《斜笔》由《横划》中间撇出来,则不合符《【Y:夕】厂字头》规格,不会选取。
若为两个以上不同的《字块》,即为《间隔分离层》,取右边《字块》。
举例:<慰>取【TU】、<璧>取【TE】、<譬>则取【TO】等字。
参考:以上《间隔分离层》。
顺便一提,《排型字块》也是一样,《撇型字块》位于顶部的最左列时,则不会被取,而取最下方及右边的《字块》。
举例:<励>取【JJ】、<剧>取【OS】等字。
**特别留意:《叠型字》中如有被包围起来的《字块》,如取两码时,都是由上而下,首码必是《上层字块》。
例如:<幽>取【SU】、<凶>则取【XU】、<病>取【YM】、<包>则取【JG】、<函>取【LU】等字。
#《全包围字块》注解:《内含字块》被三面包围,完全不会露出。
例如:<同>、<幽>、<叵>、<闲>、<咸>等字。
#《半包围字块》注解:通常只有两边有笔划包围。
例如:<病>、<或>等字。
若有三码以上时,要看是《全包围字块》还是《半包围字块》。
**如果是《全包围字块》,只剩余一码时,则会取《全包围字块》。
《全包围字块》例如:<蔺>取【HJ】、<筒>则取【SM】、<窗>则取【MQ】等字。
**如果是《半包围字块》,只剩余一码时,则取最下方《字块》,及多于两码《字块》时,会取最右边的《字块》。
《半包围字块》例如:<蜀>则取【QJ】、<篇>取【SM】、<疱>取【YG】、、<雹>取【MG】、<氲>取【YV】、<荀>取【HJ】、等字。
**简单来说,不管什么《字块》,无论是《全包围字块》或 是《半包围字块》。当只剩余一码时,则取最下方《字块》,及多于两码《字块》时,会取最右边的《字块》。
- 带钩状笔划:
《叠型字》中有转回笔锋特征,呈不互相联系的景象:
【K:矛】带钩字头:
举例:<柔>取【KP】等字。
【V:弋】带钩字头:
举例:<昏>取【VQ】、<盛>取【VD】等字。
【J:丁】带钩字头:
举例:<包>取【JG】、<召>取【JO】等字。
**特别留意:
【L-小】笔划:
统一规定为《带钩状笔划》
举例:【小】、【不】、【水】等。
例如:<尖>取【LB】、<尘>取【LC】、<丕>则取【LD】、<否>取【LO】、<丞>取【LD】、<函>取【LU】等字。
【P-木】笔划:
统一规定为《不带钩状笔划》
举例:【木】、【米】、【禾】、【采】等。
例如:<杏>取【O】、<李>取【T】、<香>取【Q】、<番>取【Q】、<秀>则取【J】等字。
**而【求】是有钩的,更因其右边一定附带有一逗点在上,故被定义为《间隔分离层》,则为《必取首码》。
例如:<裘>取【PV】等字。
参考:以上《间隔分离层》。
回《顶部》
《叠型字》的《不取首码》
原则上是如果没有《明显分离的字块》或没有《必取首码》,就都是《不取首码》。
无论看上去是合并或分离,总是不取的笔划,通常多是逗点。
例如:【丶】、【丷】、【爫】、【十】等笔划,一点头或二点头或三点头。
举例:<字>取【MT】、<常>取【MI】、<受>取【MX】、<索>取【ML】、<南>取【MT】等。
**除非是相连于最低最后的一个《逗点笔划》
举例:<零>取【MD】、<云>取【DD】、<领>取【DZ】、<冬>取【XS】、<雨>取【MN】等。
**或是两个以上相似的《分离逗点笔划》
举例:<心>取【WU】、<必>取【WR】、<斗>取【ST】等。
原则上是如果没有《明显分离的字块》或没有《必取首码》,就都只取单一码。
就好像《围型字块》左上角的一撇及一撇相连笔划,不论是简单的一撇,或是非常复杂的《字块》,都只简单看作《围型》来取码,因为输入法是以《字块》的底部来界定分类。
例如:日、白、百、者、自、首、看、着、等字,其上一撇感觉是相连的不会取,所以都一律取【Q】。既可以避免太多重码字,更加快了速度,不用输入两码。
例外:<省>取【LQ】。
理由:【L-小】《字根码》在《叠型字》中统一规定为《带钩状笔划》,为《必取首码》。
特别留意:
统一性取码,以上情况同样适用于《围型》的【口】字等。
例如:石、右、名、君等字,都一律取【O】。
统一性取码,以上情况同样适用于《横型字块》等。
例如:<差>取【C】、<羞>取【E】、<考>取【J】等。
例外:<雀>取【LE】。
理由:【L-小】《字根码》在《叠型字》中统一规定为《带钩状笔划》,为《必取首码》。
**首层是单独一《横划》,除非是《明显分离层》,否则不会去取。
例如:<豆>取【DD】、<云>取【DD】。
不取举例:<不>取【L】、<灭>取【A】、<死>取【U】。
**《撇型字块》必须位于顶部的最左边,假如《斜笔》由《横划》中间撇出来,则不合符《【Y:夕】厂字头》规格,不会选取。
**不取举例:
<石>取【O】、<死>取【U】、<右>取【O】、<百>取【Q】、<者>取【Q】。
**合符规格取首码举例:
<历>取【YJ】、<居>取【YO】、<启>取【YO】等字。
参考:以上【Y:夕】厂字头。
回《顶部》
《总结》
最后重要点是:
国家对《中文简体字体》有正式严紧的规范,《教育部国家语言文字工作委员会》组织研制以《图档》保存印发,使规范文字在不同电脑程序下,都能保持标准。并于二零一三年六月十八日,由《国务院办公厅秘书局》印发全国各部门,故形态统一标准化。虽然各地或有不同俗字,但应以官方发布的《通用规范汉字表》为准确。
例如:<聚>字,香港起码有三种以上的中文字体,写法都完全不同,不详细列举出了,简体字体官方发布为编号 取【又小:XL】。
取【又小:XL】。
有些异体字,例如:<处>官方发布为编号 取【XK】。
取【XK】。
例如:<望>官方发布为编号 取【ME】。
取【ME】。
例如:<塑>官方发布为编号 取【MC】。
取【MC】。
例如:<丽>官方发布为编号 取【DS】、顶是一划过的。
取【DS】、顶是一划过的。
例如:<呈>官方发布为编号 取【OE】。
取【OE】。
留意:还有一些如「程」、「逞」等字的简体字是【王】码,顶都是横划的。简体字现已全部改成「王」字,以【E】取码。
《建成输入法》在繁体字中,上列各字仍然保留【壬】码,顶都是一撇的,都是以【C】取码。
例如:<廷>官方发布为编号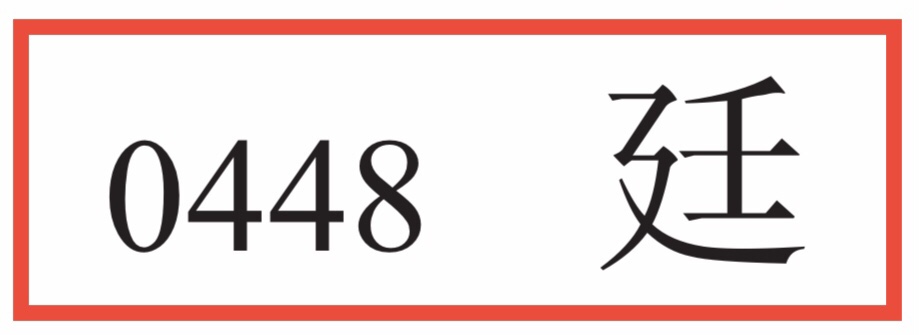 取【XC】。
取【XC】。
留意:还有一些如「妊」取【XC】、「饪」取【VC】、「淫」取【WC】、等字是【壬】码,顶都是一撇的,都是以【C】取码。
例如:<萧>官方发布为编号 取【HS】、底部三个《字块》是平过,故选最右边《直笔》与左边《直笔》,为「S」两个相似码。
取【HS】、底部三个《字块》是平过,故选最右边《直笔》与左边《直笔》,为「S」两个相似码。
留意:还有一些如「潇」取【WS】、「啸」取【OS】等字。
例如:<汽>官方发布为编号 取【WV】。
取【WV】。
留意:还有一些如「气」取【YV】、「氢」取【YV】、「氧」取【YV】等字,底部二个《字块》是平过,故都是选底部最右边。
参考:《有包围起来的形象》
例如:<画>官方发布为编号 取【DU】,【一】和【田】是分开的。
取【DU】,【一】和【田】是分开的。
例如:<监>官方发布为编号 取【DD】。
取【DD】。
留意:<监>(監)简繁虽有少许分别,但为方便记忆,<监>(監)简繁统一取【DD】。
还有一些如<尽>取【AS】、<片>取【J】等字
《建成中文输入法》是以象形为主,总体是凭着感觉,无需强记,输入多了自然学会,绝不会再忘记。
**《建成中文输入法》有点不拘小节。
例如<大>、<太>、<犬>等字都统一取【大:B】,多一个点少一个点,不会认真去分辨,所以<礻>、<衤>、<小>、<水>、<永>等字都取【小:L】,会以最近似的形态字码。
**通常附带在笔划上的逗点,都不会去理会。
举例:<兆>取【R】、<晁>取【R】、<低>取【KV】。
**除非是相连于最低最后的一个《逗点笔划》,或是两个以上相似的《分离逗点笔划》。
举例:<零>取【MD】、<云>取【DD】、<领>取【DZ】、<冬>取【XS】、<雨>取【MN】、<心>取【WU】、<必>取【WR】、<斗>取【ST】等。
**其它例如:<瓦>、<必>、<流>的右底部,都只出现一次半次,如果取【山:U】,虽则合理,但总觉像欠了一些感觉,故选定为【几:R】。
**另外例如:<母>、<曷>、<毋>等字,总感觉像《围型字块》,故选【日:Q】更为合理易记。
**又例如:<兼>等字,如果取【木:P】码,虽则亦算合理,但总觉像欠了一些感觉,而且两直笔为主,呈向下的缺口,故选【廾:H】更为合理易记。
中文有很多《字块》,作为《部首》时,型态会改变。
例如:<羊>取【F】、<匕>取【U】、<屯>取【G】等字。
**当为《部首》时会变成<翔>取【YS】、<印>取【VI】、<邨>取【VI】,为了方便初学者「见字打字」,都会跟随改变取码。
**还要留意有些相对近似的《字块》
例如:<巾>、<本>、<承>等字,都是以「底部」较低笔划为主,全是《直笔》取码。
**<巾>不取【月:M】应取【中:I】
**<本>不取【木:P】因直笔最先接触是横划,应取【十:T】
**<承>不取【小:L】同上理由,应取【牛:F】。
<今>不取【人刀:AJ】应取【人夕:AY】因斜笔有足够长度,明显呈撇型。
而<欠>不取【夕人:YA】应取【刀人:JA】因曲折笔太短,感觉不到是撇,与〈冖、宀〉等缺型较为近似,由于不呈撇状,故定为缺型。
参考:以上
有包围起来的形象
<刃>和<夕>:
<刃>取【刀:J】而<夕>取【夕:Y】因《建成中文输入法》中「撇型」的笔划,在次码中是最少有的,所以只要底部是「撇型」的笔划,全部都会取【夕:Y】,可以减少重复码。
<不>和<衣>:
<不>取【小:L】而<衣>取【弋:V】因《建成中文输入法》中「右直钩型」的笔划,亦是比较少有的,所以只要底部是「右直钩型」的笔划,全部都会取【弋:V】,可以减少重复码。
**唯一例外:
<瓦>取【几:R】参考:有关上文。
《建成中文输入法》是以「象形」为主来区分「字根」,形似绝对不是相同。取码的判断可以解理为:就如父母所生的子女,通常都会和父母有点相像,但像父亲多一点,还是像母亲多一点,每个都各有不同,要说这就要看像谁多些了。同样道理,相近似的「字块」虽然不多,但经过分析后,都很容易分辨出来。
(如有错漏或不认同者,请指教以作更正。)
回《顶部》
《文字趣味分析》
-
《繁體字》中有一個「腦」字,《腦袋》是合上的,以字根「MQ」取码,请大家留意。
而《简体字》「脑」是裂开的。其实以《象形》来看,「月」代表「肌肉」、「巛」代表「头发」、「亠」代表「头盖」,古代的人都知道头颅的重要,深信劈开了脑袋,人就没有得救,所以用《交叉》表示死亡,命也完了。
因此,《建成输入法》在《简体字》中,《脑袋》是打开的,我们只要看见上面的《横划》比较下面的《向上围型缺口》更宽长时,就表示《脑袋》是打开的,以字根「MU」取码,请大家留意。
-
还有一些如「禺」、「禹」、「禽」、「寓」、「偶」等字的底部,香港《繁体字》左边应是呈「十」字型状,左边外角不呈直角的。
但為免這些字取码混淆不清,决定参照囯家发布的《通用规范汉字表》作出更正。
《建成中文输入法》现已把上述《繁体字》也改成和《简体字》一样,全取【月:M】字码,请大家留意。
-
特别留意:「汞」取「L」,不取「P」。这是因为中文字笔顺的问题,更是中文字结构的问题,绝对不可以更改,否则学习中文一定会有困难。学生应该去了解,不可以逃避。幸好《建成中文输入法》中,是不需要拆码,所以全部《输入法字典》中,只有两个这样子的字。另一个是「叔」字,取「LX」,不取「PX」。
稍为解释一下,因为中文有些字是《拟意字》为主,是取其意思。「汞」字是工业产生的有毒性的水,而「叔」字是《上一代》即前辈中比父亲年轻的,故「上」、「小」两者都是分开,不能一直笔到底。明白这个,对手写和学习中文都是十分重要的。
回《顶部》
《展望》
-
《建成中文输入法》如果获得大众认同,我希望能尽快推出《实体应用程式》,供大家于网站免费下载,在个人电脑及手机中使用。
-
《建成中文输入法》希望能配备《智慧联想选取字词》程式,就如《拼音输入法》般,它虽有更大量的重码字,亦能快速输入中文。
-
《建成中文输入法》本「繁体版」常用字约为5450个,而「简体版」常用字约为5160个。希望能增添另一个《建成偏僻字输入》程式,令偏僻字同样可以用相同的编码输入,但不会影响到常用字的输入速度。
回《顶部》